AI Repos
1、Bella
贝拉是一款旨在成为用户数字伴侣的AI原生应用,其愿景是成为一个能陪伴、倾听并与用户共同成长的数字生命。项目不走传统功能迭代路线,而是采用“AI即架构师”的理念,分三阶段构建:第一阶段感知核心,通过“感知器-总线-处理器”模式赋予其理解多模态输入的能力;第二阶段生成式自我,利用“状态-情境-人格”引擎塑造其动态人格和行为;第三阶段主动式陪伴,建立闭环反馈系统使其能够主动学习和进化。

AI Repos
1、GenerativeAICourse
本课程是一门面向零基础的全栈生成式AI工程实践课程。它从AI基本概念和LLM的兴起讲起,重点教授如何构建可扩展的生产级AI应用,而非仅仅停留在模型训练层面。课程内容涵盖部署本地LLM、构建端到端聊天机器人、RAG、AI代理、LLMOps、MCP以及数据质量等核心主题。通过提供详细的开发环境设置指南(VS Code、Git、Python),确保学员能够亲自动手完成所有实验,将理论与实践相结合。
2、python-utcp
通用工具调用协议(UTCP)是一种灵活、可扩展的标准,用于定义和交互各种通信协议下的工具。与MCP等协议不同,UTCP专注于大规模应用和广泛互操作性,支持HTTP、WebSocket、gRPC等多种提供者类型,甚至能自动转换OpenAPI规范。它基于Pydantic模型,易于开发和使用。UTCP客户端可动态发现、搜索和调用工具,并能与大型语言模型(LLM)深度集成,实现智能、多轮的工具调用。
AI Repos
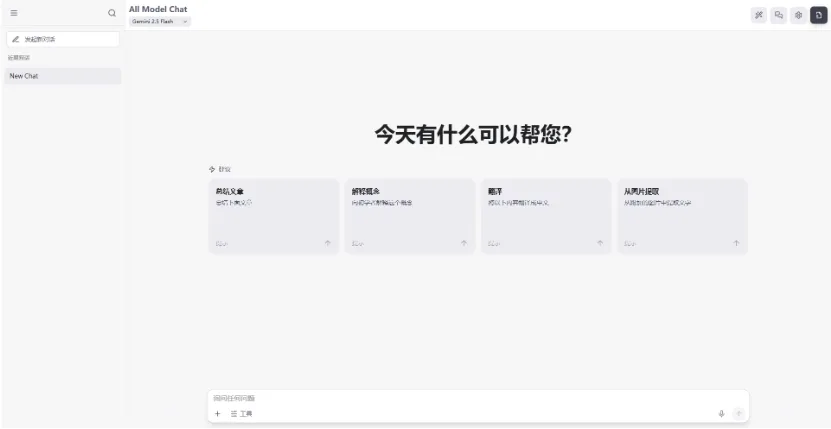
1、All-Model-Chat
All Model Chat 是一款为Google Gemini API家族设计的网页聊天应用,支持多模态输入(图片、音频、PDF等)和多种模型(如Gemini Flash、Imagen)。它提供了丰富的自定义功能,包括高级AI参数控制、思维过程展示、语音转文本/文本转语音、Google搜索增强等。应用将聊天历史自动保存在浏览器本地,确保数据隐私。用户无需安装,仅需输入API密钥即可在线体验,也可在本地进行开发部署。
AI Repos
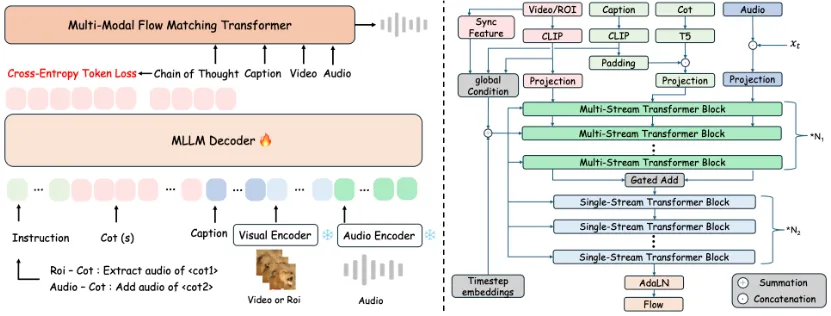
1、ThinkSound
ThinkSound是一个统一的Any2Audio生成框架,利用多模态大语言模型(MLLMs)的思维链(CoT)推理,实现从视频、文本和音频等任意模态生成或编辑音频。该项目采用三阶段交互式方法:基础声音生成、对象级精炼和定向编辑,所有过程均由CoT驱动。ThinkSound在视频到音频任务上达到了SOTA,并支持交互式、细粒度的声音编辑。项目已开源,并提供推理脚本、网页界面和Hugging Face在线演示,但仅限研究和教育用途。
AI Repos
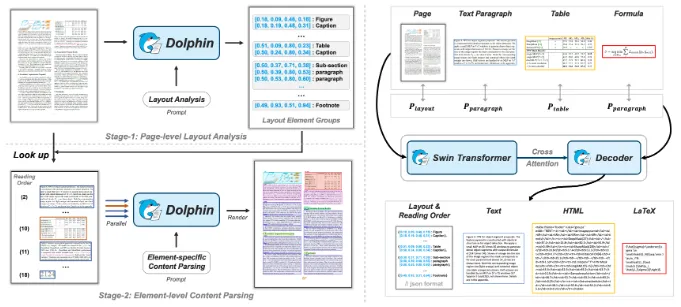
1、Dolphin
Dolphin(Document Image Parsing via Heterogeneous Anchor Prompting)是字节跳动推出的一种新型多模态文档图像解析模型,采用“先分析后解析”的两阶段方法。它首先通过生成自然阅读顺序的元素序列进行页面级布局分析,然后利用异构锚点和任务特定提示高效并行解析文档元素。Dolphin在各类页面和元素级解析任务上表现出色,同时具备轻量化架构和并行解析机制,确保高效率。项目已开源代码和预训练模型,并支持TensorRT-LLM和vLLM加速推理,可处理多页PDF文档。