目录
AI Repos
1、mcp-playwright
基于Playwright的MCP服务项目:mcp-playwright,可以让AI与网页交互,执行打开网页、点击按钮、输入文字、截图、运行JavaScript等操作。可以用来做自动化测试、数据抓取、网页分析等应用。通过mcp-playwright实时与网页交互,获取网页上的动态数据,使得AI能处理最新信息。执行JavaScript代码,AI就可以对网页进行更复杂的操作。
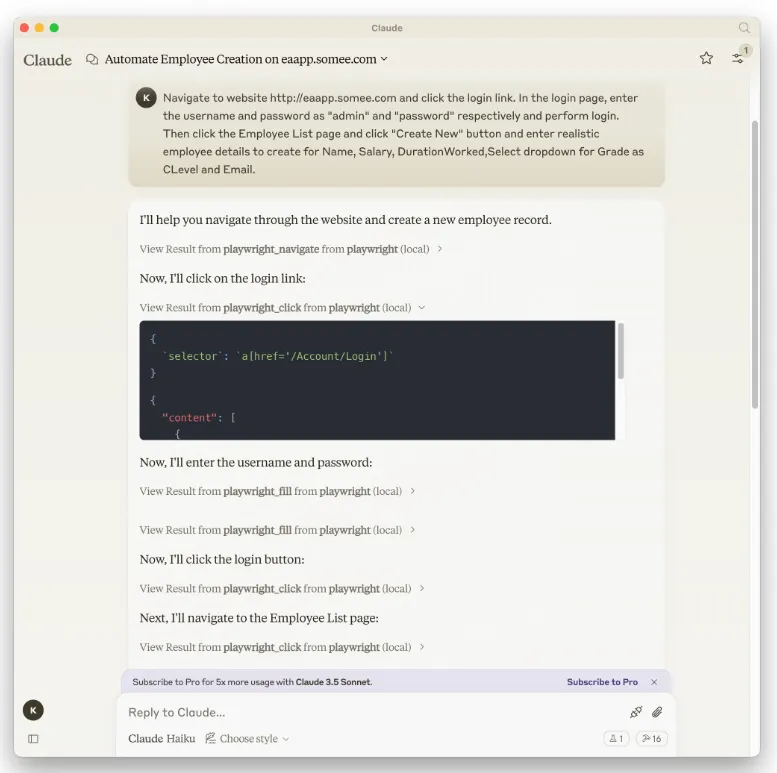
2、local-deep-research
强大的 AI 研究助手,可在本地运行执行深度、迭代式研究分析,支持多种 LLM 和网络搜索,结合隐私保护和强大研究能力于一体。安装简单,并提供终端和网页界面两种使用方式,可配置使用本地 Ollama 模型或云端 LLM。
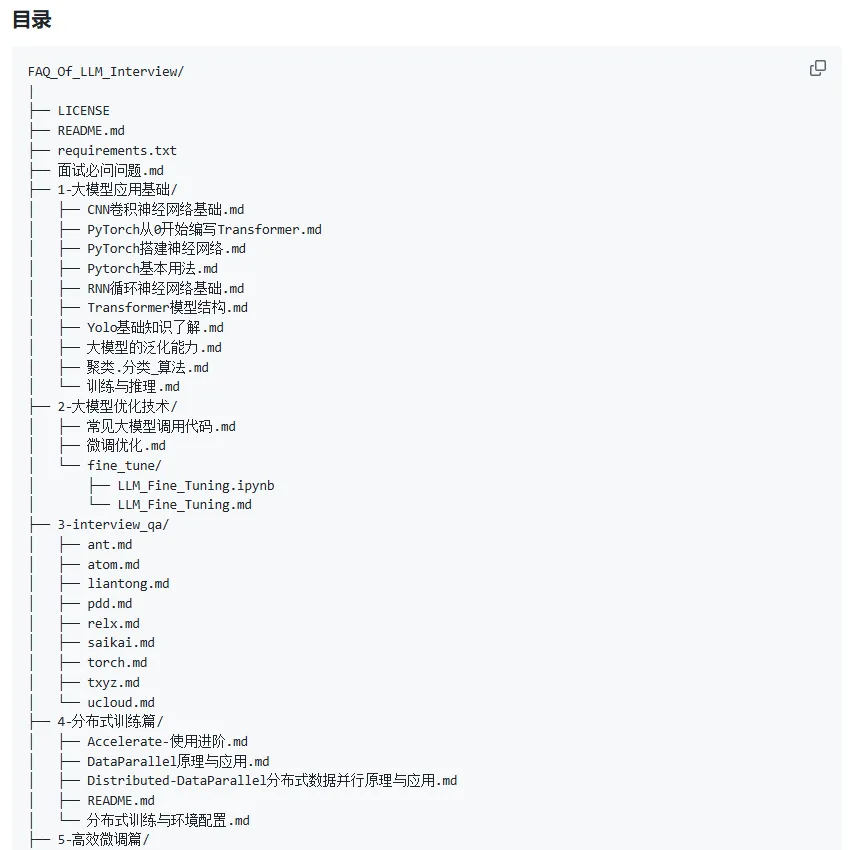
3、FAQ_Of_LLM_Interview
面向大模型算法岗求职者的面试题集锦,包含大模型应用基础、优化技术、分布式训练、微调技术等内容,涵盖了真实企业面试经验和常见问题解析。特别适合准备大模型算法岗面试的技术人员参考学习。
AI News
1、Hugging Face 发布 Open R1 第三弹更新:编程领域新突破
Open R1: 第三弹更新是由 Hugging Face 的 Open R1 项目团队发布的最新进展报告,旨在分享他们对 DeepSeek-R1 的完全开源复刻工作的最新成果。本次更新聚焦于编程领域,主要是发布了一些新的数据集、基准测试以及媲美 R1 的编程模型 OlympicCoder。
2、谷歌 Gemini 2.0 Flash 原生图像生成功能正式开放
谷歌的 Gemini 2.0 Flash 的原生图像生成功能现已正式开放。该功能首次测试于 2024 年 12 月,现在,开发者可以通过 API 或 AI Studio 的界面测试 Gemini 2.0 Flash EXP 模型的图像生成和编辑功能。与 Stable Diffusion、Flux 不同,Gemini 2.0 Flash EXP 模型不仅能够通过自然语言生成图片,还能将图像与文本混合输出,甚至支持多轮对话,逐步调整和优化图像。
3、阿里通义 VACE:All-in-One 视频生成与编辑模型
VACE 是阿里通义团队发布的一款 All-in-One 视频生成和编辑模型,它在一个模型内集成了多种功能,包括:
(1)Move-Anything:轻松移动视频中的任何元素,无论是人物、物体还是背景。
(2)Swap-Anything:交换视频中的任何元素,实现创意无限的视频编辑。
(3)Reference-Anything:引用任何元素进行视频创作,提升创作的灵活性和多样性。
(4)Expand-Anything:扩展视频内容,增加视频的丰富性和深度。
(5)Animate-Anything:为任何元素添加动画效果,让视频更加生动和有趣。
此外,VACE 还支持视频重渲染,能够在保留内容、结构、主体、姿态和动作的同时,对视频进行高质量的重新渲染。
4、西湖大学推出AI文本检测模型,破解“AI幻觉”难题
西湖大学研究团队研发出一种新模型,利用无监督算法检测AI生成文本,旨在应对人工智能创作日益普及带来的挑战。团队负责人张岳教授指出,AI生成的“幻觉”问题可能导致虚假信息传播,尤其在教育领域影响学生能力评估。传统有监督学习方法受限于训练数据,而新模型无需预标记数据,通过识别模式提升准确性。Demo版已展示并获关注,团队正推进实际应用合作,以确保内容真实可靠。
5、Flower Labs获2360万美元打造全开放AI混合计算平台
Flower Labs推出Flower Intelligence,一个分布式云平台,革新AI模型部署方式。该平台采用混合计算策略,支持本地设备运行AI模型以提升速度与隐私保护,并在需强算力时切换云端,已获Mozilla等企业青睐。作为首家全开放模型平台,它整合Meta等开源模型,增强开发者灵活性。其云服务采用端到端加密保障数据安全。公司筹资
6、北京中小学推11个AI应用场景与7个“京娃”智能体
北京市教委计划在中小学推出11个AI应用场景,包括智能备课、课堂监测、错题分析、外语学习助手等,覆盖教学、管理、评价等多领域。同时,启动7个“京娃”智能体,如“京小宝”提供幼儿成长建议、“京小学”定制学习路径、“京小健”关注身心健康等。这些举措旨在通过AI技术促进五育融合与个性化发展。市教委强调将培养学生数据安全意识,防范过度依赖风险。此前,北京已在多所学校试点AI应用,未来将持续升级“京娃”功能。
7、英国首相推AI替代部分公务员工作以提升效率
英国首相基尔・斯塔默计划利用AI和数字化替代部分公务员任务,以提升政府效率并节省超450亿英镑开支。他认为,AI可接手标准工作,让公务员专注需要人类判断的领域,同时拟招募2000名技术学徒。此举引发工会担忧,FDA秘书长戴夫・彭曼称需明确资源减少下的服务保障,工会呼吁合作而非指责。斯塔默还计划减少监管和非政府组织数量,强调改革旨在优化服务,而非大幅裁员,与特朗普的激进措施形成对比。
8、MiniMax拟收购AI视频初创鹿影科技
据蓝鲸新闻报道,AI视频初创公司鹿影科技或将被MiniMax收购,双方已达成初步意向,正在推进流程。鹿影科技2024年天使轮估值约1亿人民币,因后续融资困难,其AI视频技术积累促成与MiniMax合作。成立于2023年的鹿影科技专注视觉模型,推出动漫AI视频平台YoYo,曾获蓝驰创投等投资。MiniMax尚未回应。此交易被视为双方互利之举,具体细节待进一步披露。
9、腾讯元宝携手腾讯文档实现一键上传与导出
腾讯宣布腾讯元宝与腾讯文档深度整合,支持一键上传和导出功能,提升办公效率。用户可通过移动端或Web端上传多种格式文档(如表格、PPT、PDF等),元宝直接解析处理,并将回答导出为腾讯文档,方便编辑与分享。此升级简化了以往繁琐的复制粘贴流程,支持多文件混合上传,适用于整理分析、会议展示等场景。目前,手机版和Web端已上线,电脑版即将推出,进一步优化协作体验。
10、Luma开源IMM技术,图像生成效率提升10倍
Luma开源图像模型预训练技术IMM(Inductive Moment Matching),以高效和稳定特性突破生成式AI瓶颈。IMM采样效率提高10倍以上,在ImageNet256×256仅8步达1.99FID,CIFAR-10仅2步达1.98FID,超越扩散模型和一致性模型。其“推理优先”设计和强大鲁棒性打破传统算法限制,开源代码已在GitHub发布。业界认为,IMM或引发图像生成范式转变,未来可扩展至视频等多模态领域,标志着Luma在AI竞赛中的重要进展。
11、潞晨科技开源Open-Sora 2.0挑战Sora,成本降至20万美元
潞晨科技推出开源视频生成模型Open-Sora 2.0,仅耗资20万美元训练出110亿参数模型,性能直逼OpenAI Sora。VBench评测显示其与Sora差距缩小至0.69%,超越腾讯HunyuanVideo等模型。采用3D自编码器、Flow Matching及高效并行训练等技术,成本降低5-10倍,采样效率提升10倍。Open-Sora开源全流程代码,推动生态发展,半年内获近百学术引用。高压缩比自编码器将推理时间缩短至3分钟,显著降低门槛,引领视频生成技术新风向。
12、阿里巴巴“新夸克”升级为AI超级框,开启多模态交互时代
阿里巴巴推出AI旗舰应用“新夸克”,基于通义大模型升级为“AI超级框”。它融合强大推理与多模态交互能力,支持实时互动、任务执行与策略调整,超越传统搜索,满足工作、学习、生活需求。未来,通义系列最新成果将优先接入,用户可体验前沿AI技术。CEO吴嘉表示,新夸克旨在成为个人全能助手,以一个无边界的AI入口,引领用户进入AI世界。
13、智谱AI再获珠海5亿元融资,加速GLM大模型生态建设
珠海华发集团向智谱AI投资5亿元,支持其GLM大模型技术创新与生态发展。此前,智谱已获30亿元及超10亿元融资,投资者包括北京、杭州等多地国资。此次珠海加入,标志其国资支持进一步扩大。作为估值超200亿的AI领军企业,智谱计划2025年开源基座、推理、多模态等新模型。珠海期待通过合作推进“云上智城”建设,智谱则强调开放合作,携手推动AI产业繁荣。
14、Remade AI开源8款Wan2.1特效LoRA,推动AI视频创作热潮
Remade AI在Hugging Face发布8款基于Wan2.1模型的开源特效LoRA,包括“挤压”“蛋糕化”等,为AI视频生成带来创意突破。依托阿里Wan2.1 14B I2V模型,这些模块将静态图像转为动态特效,适用多类对象,效果惊艳。团队强调开源理念,通过Discord收集需求,承诺持续免费更新。特效推出即获数千下载,被誉为“Wan2.1创意助推器”,有望降低创作门槛,掀起AI视频革新热潮。
Others
1、一图解释MCP
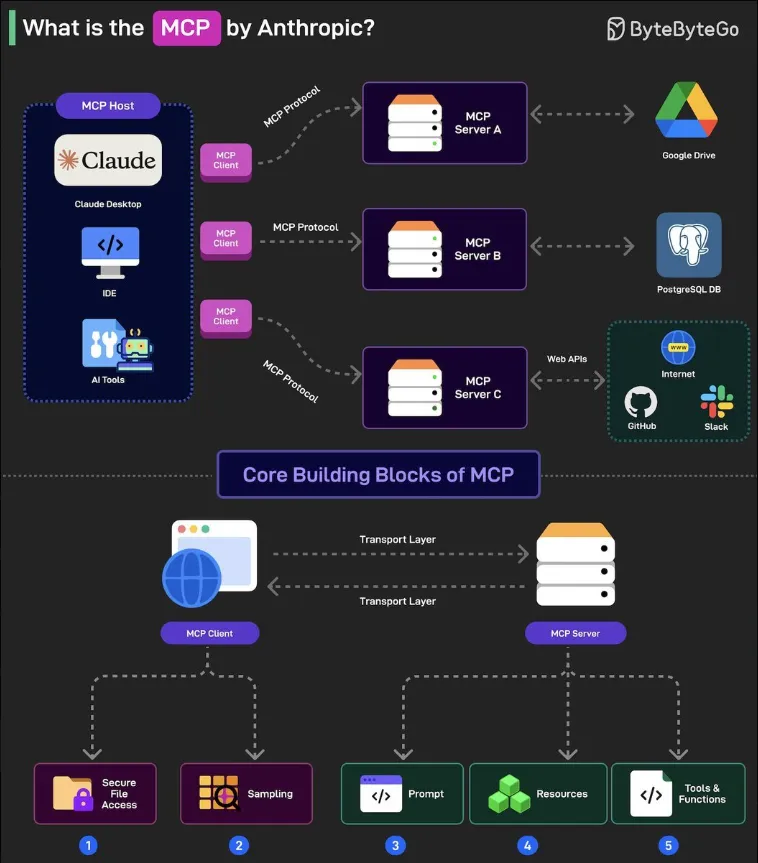


本文作者:junglehxj
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!