目录
AI Repos
1、chatlog
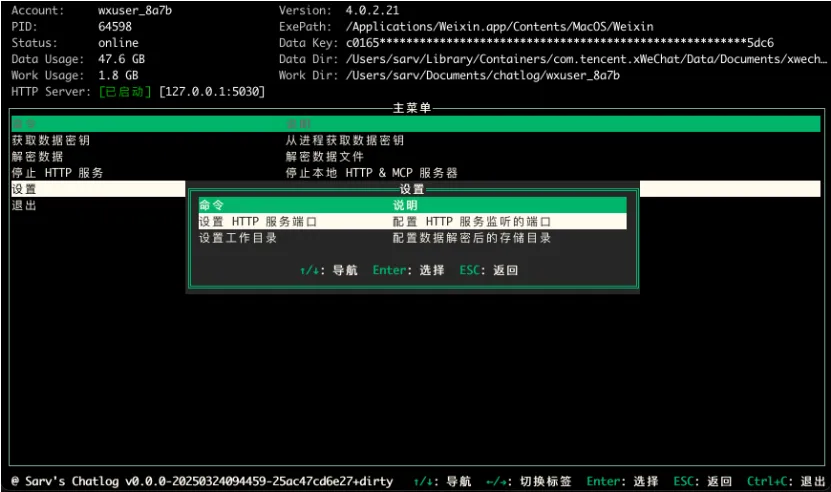
一个基于 MCP 实现聊天记录总结和查询的开源工具,完美解决我们群聊消息过多没时间查看的问题。提供简单易用的操作界面和命令行工具,支持微信 3.x 和 4.0 版本,实现查询聊天记录、联系人、群聊以及最近对话等信息。通过 MCP SSE 协议,可与任何支持 MCP 的 AI 助手集成使用,如 Claude、ChatWise、Cherry Studio 等。
2、Awesome-RAG-Vision
收集整理了视觉 RAG 领域的前沿论文和研究资源,涵盖视觉理解、视频理解、多模态和视觉生成等领域的前沿 RAG 论文,并进行了清晰的分类。不仅收集了大量高质量的论文,还包含各类教程资源,旨在帮助研究者快速了解该领域的最新进展。

AI News
1、字节跳动发布Multi-SWE-bench数据集,推动多语言代码自动修复技术发展
字节跳动豆包大模型团队推出全球首个多语言软件工程数据集Multi-SWE-bench,涵盖Python、Java、Go等8种主流编程语言,包含1632个真实GitHub问题实例,通过统一测试标准和专业审核构建。该数据集旨在系统性评估大模型在多语言环境下的代码自动修复能力,推动自动化编程技术向实用化、工程化方向发展,有望显著提升开发效率和软件质量,为开发者提供更智能的错误修复支持。
2、商汤科技发布多模态大模型日日新V6并开放API,加速AI应用落地
商汤科技正式推出新一代多模态大模型“日日新V6”,在文本、图像、视频等跨模态任务中实现显著性能提升,对标国际顶尖模型。该模型API将于次日开放,为开发者提供高效工具,推动智能客服、医疗分析、内容创作等场景应用落地。此次升级进一步巩固商汤在AI领域的技术优势,助力中国人工智能生态的全球化发展。
3、谷歌发布Vertex AI Media Studio文生视频套件,AI赋能一站式视频创作
谷歌推出Vertex AI Media Studio文生视频套件,整合Imagen3、Veo2等多项AI技术,实现从文本到视频的全流程自动化生成。该平台支持动态画面渲染、智能配音配乐,大幅降低视频制作门槛,适用于营销、教育等多场景需求。谷歌同时强调内容安全与版权保护,采用SynthID数字水印技术。这一创新工具将重塑视频创作模式,推动AI在多媒体领域的深度应用。
4、IBM发布z17新一代主机,Telum II处理器赋能企业级AI大规模运算
IBM推出搭载Telum II处理器的新一代z17主机,专为大规模AI运算优化,AI推理能力较前代提升50%,每日可处理超4500亿次推理操作。该主机集成watsonx等AI助手工具,支持250余种企业应用场景,包括金融风控、智能客服等,同时通过Spyre™加速器强化生成式AI能力。z17延续IBM主机在企业核心业务中的关键地位,为银行、电信等行业提供高性能、低延迟的AI基础设施支持,助力企业挖掘数据价值。
5、xAI推出Grok 3 API进军多模态AI市场,图像分析能力对标GPT-4o与Gemini
马斯克旗下xAI公司正式开放Grok 3 API服务,提供标准版Grok 3和轻量版Grok 3 Mini两种模型,新增图像分析与推理功能,定价策略高于行业平均水平。该模型虽具备13万标记的上下文窗口,但未达宣传的百万级处理能力,且在政治议题上仍存在立场偏向问题。此次发布标志着xAI加速商业化进程,与OpenAI、Google等巨头在AI服务市场展开直接竞争。
6、WordPress.com推出AI网站构建器,用户通过对话式交互快速生成专业网站
WordPress.com发布全新AI驱动网站构建工具,用户只需通过自然语言描述需求,系统即可自动生成包含文本、图片和版式的完整网站,整个过程仅需几分钟。该工具目前处于抢先体验阶段,支持个人和商业网站创建,但需订阅每月18美元起的托管服务才能正式使用。虽然AI生成的网站内容仍需人工优化,但这一创新显著降低了网站建设门槛,为WordPress平台注入了智能化新功能。
7、宜人智科"智语大模型"完成备案,AI赋能金融科技迈入合规新阶段 宜人智科宣布其自主研发的"智语大模型"成功完成生成式AI服务备案,成为金融领域首批合规大模型之一。该模型专为金融场景设计,具备智能风控、客服、营销等核心功能,将推动金融服务智能化升级。此次备案既是企业响应国家AI监管政策的重要举措,也标志着金融科技行业在AI合规应用方面取得突破性进展,为后续商业化部署奠定基础。
8、印度Ziroh Labs推出轻量化AI系统,突破高性能硬件依赖降低应用门槛
印度AI初创公司Ziroh Labs联合顶尖技术院校研发出一套创新AI系统,可在普通计算设备上高效运行大型AI模型,无需依赖NVIDIA等高端计算芯片。该系统通过算法优化显著降低硬件需求,使中小企业和教育机构能以更低成本应用先进AI技术,推动人工智能在资源有限环境中的普及。这一突破性进展有望加速全球AI技术的民主化进程,特别惠及发展中国家市场。
9、Synthesia与Shutterstock达成战略合作,AI数字人技术获视频资源加持
英国AI公司Synthesia与Shutterstock签署视频内容授权协议,将利用后者海量视频资源提升数字人表情、语音和肢体动作的逼真度。Synthesia通过签约真人演员生成企业级数字人形象,服务劳埃德银行等客户,并为演员提供股权激励。此次合作在AI版权争议背景下达成,公司强调不会直接使用Shutterstock演员形象,而是用于算法训练,引发对英国版权政策的新一轮讨论。
10、Gradio 5.24重磅升级:专业级AI图像编辑组件开启开源工具新纪元
开源AI框架Gradio发布5.24版本,其全新ImageEditor组件实现媲美Photoshop的专业图像编辑功能,包括精准缩放平移、透明度调节和多图层管理。此次升级显著提升了AI图像处理演示的专业度,为开发者构建图像修复、生成等应用提供了更强大的交互工具。该版本将推动开源社区AI演示质量的整体跃升,标志着开源工具在专业图像处理领域的重要突破。
11、Deep Cogito发布Cogito v1开源代码模型家族,70B版本性能超越Llama 4引领AI编程新浪潮
Deep Cogito推出Cogito v1 Preview系列开源代码模型,包含3B至70B多种参数规格,其中70B版本在代码生成和复杂推理任务上超越Meta的Llama 4 109B MoE模型。该系列专为编程优化,支持双模运行和AI代理功能,已通过Fireworks AI等平台开放API接口。此次发布标志着开源AI代码模型进入性能竞争新阶段,其后续更大规模模型的规划或将重塑行业格局。
12、谷歌AI Studio发布Gemini-2.0-flash-live-001模型,开启实时多模态AI交互新时代
谷歌AI Studio正式推出Gemini-2.0-flash-live-001多模态模型,取代实验版本并启用计费功能。该模型针对低延迟场景优化,显著提升了流式音频、视频和文本的实时处理能力,适用于虚拟助手、会议分析等即时交互应用。此次更新标志着谷歌在实时AI技术领域的重要突破,为开发者提供了更强大的生产级工具,将推动教育、企业服务等多个行业的智能化创新。
13、谷歌开源A2A协议重塑AI智能体生态,实现跨平台智能协作新时代
谷歌云发布开源Agent2Agent(A2A)协议,通过标准化通信框架解决不同AI智能体间的互操作难题。该协议基于HTTP/JSON等现有标准,支持多模态数据交换和长期任务管理,已获50余家科技巨头支持。A2A允许异构智能体通过"智能体卡片"发现彼此能力并协同完成任务,将显著提升企业自动化流程效率,推动AI应用从单点智能迈向系统级协作。这一突破性协议预计将加速智能体技术在商业场景中的规模化落地。
14、阿里云发布MCP智能体开发服务,5分钟快速构建大模型应用
阿里云正式推出全生命周期MCP(Model-Connect-Protocol)服务,通过标准化协议连接大模型与应用,用户仅需5分钟即可创建具备自主决策能力的智能体。该服务首批集成50余款阿里巴巴及第三方应用,覆盖生活服务、办公协同等多个场景,并支持200多款大模型的无缝对接。这一创新显著降低了大模型应用开发门槛,推动AI技术向产业化应用加速落地。
15、科大讯飞星火X1迎来重大升级,国产AI模型性能直追国际顶尖水平
科大讯飞宣布将对其深度推理模型星火X1进行重要升级,新版本在推理能力、文本生成和语言理解等方面将显著提升,性能可对标OpenAI o1和DeepSeek R1等国际领先模型。该模型基于1万张国产910B算力卡训练,展现了国产AI技术的突破性进展。预计三个月内完成升级的星火X1有望在数学推理等关键领域实现超越,标志着中国在人工智能领域的竞争力持续增强。
16、商汤科技发布多模态大模型SenseNova V6系列,开启智能交互新纪元
商汤科技推出全新多模态大模型SenseNova V6系列,包含6200亿参数的Pro版本及专注视频理解的Video版本等,具备强大的跨模态融合与推理能力。该模型可实现手写解题、语音引导等自然交互,性能对标国际主流模型GPT-4.5和Gemini2.0。商汤通过强化推理、交互与记忆三大核心技术,布局教育、翻译等应用场景,并与傅利叶合作推进具身智能发展,引领多模态AI交互新时代。
17、复旦联合阶跃星辰发布OmniSVG模型,开创AI矢量图生成新纪元
复旦大学与阶跃星辰合作推出多模态SVG生成模型OmniSVG,支持文本描述、图片转换及角色参考三种生成方式,可高效创作从简单图标到复杂动漫的矢量图形。该模型基于Qwen-VL架构创新实现结构与几何解耦,大幅提升生成质量与效率。作为数字艺术领域的突破性技术,OmniSVG将重塑广告设计、游戏开发等行业的创作流程,展现产学研协同创新的典范价值。
18、语音合成技术双突破:Orpheus TTS开源商用 vs 亚马逊Nova Sonic原生多模态
近期语音合成领域迎来两项重要进展:开源的Orpheus TTS模型支持多语言商用部署,但中文表现尚有提升空间;亚马逊推出的Nova Sonic则采用创新架构,实现端到端语音到语音转换,目前仅通过API提供服务。这两项技术分别代表了开源可商用和原生多模态两种不同的语音合成发展方向,将为智能客服、内容创作等领域带来新的技术选择。


本文作者:junglehxj
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!