目录
AI Repos
1、UI-TARS
UI-TARS-1.5 是字节跳动开源的多模态智能体,基于强大的视觉语言模型构建,通过强化学习实现高级推理,显著提升了在虚拟世界中执行多样化任务的能力和适应性。相较前期模型,1.5 版本在 OSWorld、Windows Agent Arena 和 WebVoyager 等基准测试中取得了领先成果,并在 Poki 游戏和 Minecraft 等环境展现出卓越性能。该项目提供了快速上手指南、部署和后处理说明,以及针对桌面、移动和基础任务的不同提示模板。尽管性能强大,UI-TARS-1.5 仍面临潜在的滥用、高计算需求和幻觉等局限性,未来将致力于提升模型能力并探索在实际应用中的潜力。

2、agent-api
Simple Agent API 是一个稳健的、可用于生产环境的应用程序,旨在将 AI 智能体作为 API 进行服务化。它包含一个用于处理 API 请求的 FastAPI 服务器、一个用于存储智能体对话会话、知识和记忆的 PostgreSQL 数据库,以及一组预构建的智能体作为起点。该框架支持使用 Docker Compose 快速启动,默认采用 GPT 4.1 模型,并可通过 Agno Playground 或 Agent UI 进行交互。开发者可以轻松配置 API 密钥,利用预构建的 Web 搜索、Agno 助手和金融智能体,并支持通过 Dockerfile 部署到各种云平台。

3、Muyan-TTS
Muyan-TTS 是一款为预算 5 万美元的播客应用设计的可训练文本转语音(TTS)模型。它在超过 10 万小时的播客音频数据上进行预训练,能够实现高质量的零样本 TTS 合成,并支持通过数十分钟的目标语音进行说话人自适应,高度可定制化。该项目开源了零样本和少量样本 TTS 模型权重,以及从基础模型到说话人自适应 SFT 模型的训练代码和技术报告。Muyan-TTS 在单个 A100 GPU 上实现了快速的合成速度,但目前仅支持英语输入。提供了详细的安装、模型下载、快速上手、API 使用和训练指南。
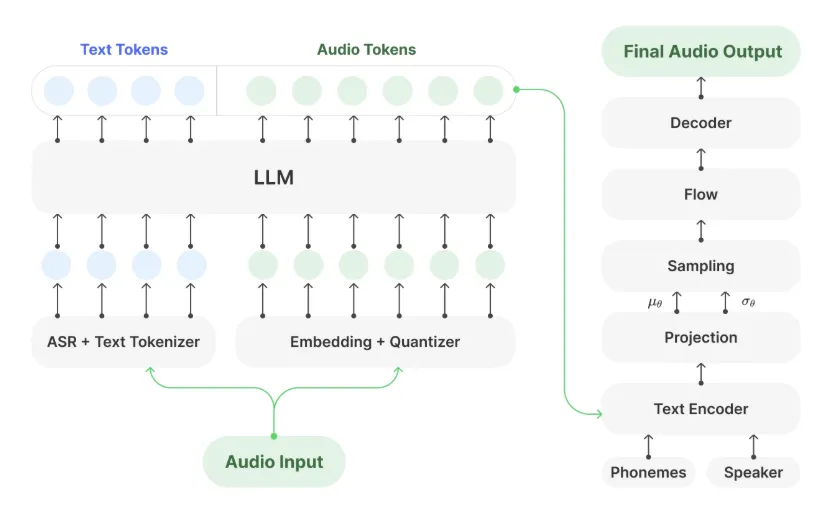
4、agentset
Agentset 是一个面向开发者的开源检索增强生成(RAG)平台。其技术栈包括 Next.js、TypeScript、Tailwind、Shadcn/ui、Upstash、Supabase、Prisma、BetterAuth、Turborepo、Stripe、Resend 和 Vercel。该平台提供自托管指南,开发者可通过简单的步骤安装依赖、配置环境变量、迁移数据库并启动本地 Upstash 工作流服务器和开发服务器。Agentset 采用 MIT 许可证开源,旨在为开发者提供构建 RAG 应用的基础设施。

5、LocalSite-ai
LocalSite AI 是一款现代 Web 应用,利用 AI 根据自然语言提示生成完整的 HTML、CSS 和 JavaScript 代码,实现一键创建网页。它支持 DeepSeek、兼容 OpenAI API 的自定义接口以及 Ollama 和 LM Studio 等本地模型。用户可以通过简洁的界面输入提示,实时预览桌面、平板和移动视图,并直接在浏览器中编辑生成的代码。LocalSite AI 提供多种 AI 提供商选择,并计划集成更多模型和高级代码生成功能,如选择框架、多文件生成和 Agentic 编辑能力。该项目采用 Next.js、React、Tailwind CSS 等技术栈,并支持 Vercel 等平台部署。

6、Local_Chat_RAG
Local Chat RAG 是一款本地运行、注重隐私的检索增强生成(RAG)聊天应用。用户可以上传 DOCX、PDF 等文档,并向基于本地开源 LLM(如 Mistral、Llama2)的应用提问,获取带有文档来源的答案,所有数据处理均在用户本地进行,无云端交互。该应用采用 Vite、React、TypeScript、Zustand 和 Chakra UI 构建现代用户界面,后端使用 FastAPI 提供 API,并集成 Ollama 进行本地 LLM 和嵌入。Local Chat RAG 具有模块化、可扩展的代码结构和完善的文档。

AI News
1、ChatGPT 推出 PDF 导出功能,优化深度研究报告分享
ChatGPT 新增了将深度研究报告直接导出为 PDF 格式的功能,解决了以往复制内容时格式丢失的问题,方便用户分享研究成果。ChatGPT 的深度研究功能能够自动进行复杂的多步骤研究,整合网络信息生成详尽报告。用户现在可以通过新增的“下载为 PDF”选项,轻松保存高质量的报告文件。此外,OpenAI 还为团队订阅用户推出了新的 GitHub 连接器,旨在增强 ChatGPT 在代码管理和团队协作方面的能力,进一步提升用户体验和团队合作效率。
2、苹果发布 FastVLM 模型:iPhone 上极速运行的高分辨率视觉语言模型
苹果发布 FastVLM,一款专为 iPhone 等移动设备优化的高效视觉语言模型。其核心创新在于 FastViTHD 混合视觉编码器,实现了高达 85 倍的编码速度提升,并通过动态分辨率调整、层次化令牌压缩和硬件优化,在保持性能的同时显著降低计算和内存需求。FastVLM 在 SeedBench、MMMU 等基准测试中表现出色,并支持 CoreML 集成,可在 iPhone 上实现实时多模态推理,应用于 AR、图像编辑和医疗影像分析等场景。苹果已开源 FastVLM 的代码和模型,标志着其在移动端 AI 战略上的重要一步。
3、字节跳动开源 8B 参数代码模型 Seed-Coder,引领智能编程新风潮
字节跳动 Seed 团队发布了开源代码模型 Seed-Coder,包含 Base、Instruct 和 Reasoning 三个变体,参数规模 8B,上下文长度 32K,并采用 MIT 协议。Seed-Coder 的核心创新在于“模型为中心”的数据处理方式,利用小型 LLM 自动策划和过滤代码数据,显著提升了数据质量和模型性能。在 SWE-bench、Multi-SWE-bench 和 IOI 等基准测试中,Seed-Coder 均超越同级别竞品,展现出强大的代码生成、补全、编辑和推理能力,堪称轻量级代码模型的佼佼者。字节跳动此次开源进一步推动了 AI 在软件工程领域的应用。
4、NVIDIA AI 发布 Audio-SDS:SDS 技术赋能音频扩散模型,革新音效生成与多任务处理
NVIDIA AI 研究团队推出了 Audio-SDS,通过将 Score Distillation Sampling (SDS) 技术扩展到文本条件音频扩散模型,实现了音效生成、音源分离及多任务音频处理能力的显著提升。Audio-SDS 无需重新训练即可将预训练音频扩散模型转化为多功能工具,支持文本条件控制的高效推理。该技术在音源分离、音效合成、FM 合成和语音增强等任务中表现卓越,降低了开发成本,并为娱乐、智能设备和教育创作等领域带来广泛的应用前景。NVIDIA 已开源相关论文和音频样本,推动 AI 音频创新。
5、Fellou 发布全球首款 AI 智能浏览器,效率提升 5 倍
Fellou 号称全球首款 Agentic 浏览器,利用 AI 自动化实现深度研究和跨平台工作流一键完成。其深度研究模式通过并行搜索多个平台,数分钟内生成完整报告;深度工作流模式则支持自然语言指令触发跨平台任务自动化,如社交媒体发帖和邮件发送。Fellou 基于 Claude3.5 和 OpenAI 等先进 AI 系统,注重用户隐私,数据本地处理并端到端加密。官方数据表明,Fellou 完成复杂任务的速度比手动操作快 5.2 倍。该浏览器提供免费版本,高级功能需订阅,项目已开源。
6、腾讯开源多模态视频生成框架 HunyuanCustom,强调高一致性与强控制力
腾讯开源了全新的多模态定制视频生成框架 HunyuanCustom,该框架基于 HunyuanVideo 打造,核心特点是“主体一致性”和“多模态灵活输入”。HunyuanCustom 支持文本、单/多图、参考音频甚至已有视频片段作为输入,生成定制化视频,并着重保证视频中人物或物体身份的一致性。该框架在虚拟人物广告、虚拟试穿、唱歌头像生成和智能视频编辑等领域展现出巨大潜力,旨在降低多模态视频创作门槛,为开发者和内容创作者提供高质量、高一致性的视频生产能力。
7、腾讯发布 PrimitiveAnything 框架,革新 3D 形状生成方式
腾讯 AIPD 与清华大学联合推出了 PrimitiveAnything 框架,将 3D 形状抽象重新定义为原始组件生成任务。该框架采用解码器式变换器,通过统一的参数化方案和自动回归生成方式,高效捕捉复杂形状的分解模式。PrimitiveAnything 支持多种原始形状类型,并利用级联解码器建模属性依赖关系。研究团队构建了包含人工标注的 HumanPrim 数据集进行评估,结果表明该框架在重构准确性和与人类抽象模式的一致性上表现优异,并支持从文本或图像生成可编辑的 3D 内容,实现高建模质量和存储节省,适用于高效互动 3D 应用。
8、谷歌 Gemini 2.5 Pro 突破视频理解极限,支持 6 小时分析与 YouTube 链接解析
谷歌 Gemini 2.5 Pro 在视频理解能力上实现重大升级,不仅能分析长达 6 小时的视频,还具备 200 万 Token 的超大上下文窗口,并首次支持通过 API 直接解析 YouTube 链接。该模型在 VideoMME 基准测试中准确率高达 84.7%。Gemini 2.5 Pro 能够一次性处理长视频内容,精准定位关键时刻,并进行复杂的跨时间分析。这项技术基于 3D-JEPA 和多模态融合技术,为教育、创意产业和商业分析等领域带来创新应用,并通过低分辨率处理模式降低了长视频分析成本。
9、Anthropic Claude API 新增网页搜索功能,直指谷歌搜索
Anthropic 于 5 月 8 日宣布为其 Claude API 引入网页搜索功能,允许开发者构建能够访问最新网络信息的智能应用程序。通过启用该功能,Claude 在接收需要最新信息的请求时,将利用推理能力判断是否需要进行网络搜索,并能进行渐进式搜索以生成更全面的答案,且附带来源引用。该功能在金融服务、法律研究和开发者工具等领域具有广泛的应用潜力,使得 Claude 能够提供更准确和及时的信息服务,直接挑战以谷歌为首的传统搜索引擎。
10、QwenChat 上线网页开发功能,一句指令生成精美网页
QwenChat 近日推出了全新的网页开发(Web Dev)功能,用户只需输入一句自然语言指令,例如“创建一个水果电商网站”,系统即可自动生成结构清晰、风格美观的网页代码并支持预览和调整。该功能不仅限于电商网站,还能用于制作音乐播放器、单词记忆卡片等多种网页应用,为不具备编程技能的用户提供了便捷的网页创建方式。目前,该功能已集成至 QwenChat 平台(chat.qwen.ai)。
11、腾讯混元 T1-Vision 上线元宝,深度理解图片内容
腾讯混元 T1-Vision 模型已上线元宝 App,具备深度理解图片内容的能力,能够精确捕捉图片背后的关键信息。用户上传图片后,无论是不常见的植物、外文游戏界面还是复杂决策场景,元宝都能快速给出详细解答和分析。其“深度思考 T1”功能支持图文之间的多模态原生思维链,反应速度更快,完答速度提升 1.5 倍。元宝旨在帮助用户更高效准确地获取和理解信息,已在学习、工作和日常生活中展现出多方面优势,用户可通过腾讯元宝官方网站下载使用。


本文作者:junglehxj
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!