目录
AI Repos
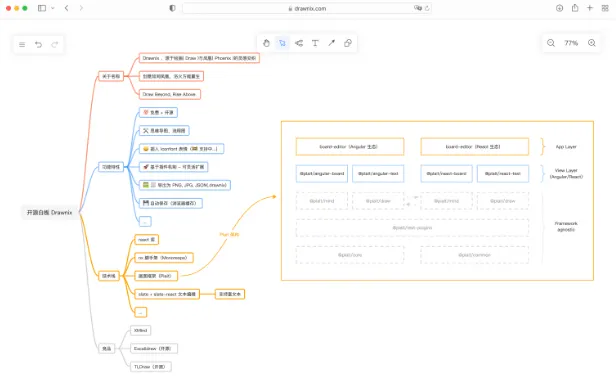
1、drawnix
Drawnix 是一款免费开源的一体化白板工具,集成了思维导图、流程图、自由画等多种功能。它支持插入图片、导出为 PNG/JSON、自动保存、撤销重做、无限画布以及主题模式。Drawnix 基于灵活的插件机制和底层 Plait 框架,支持 Mermaid 语法转流程图和 Markdown 文本转思维导图。该工具旨在通过直观的创作方式和持续迭代,为用户提供高效且富有创造力的可视化表达体验,其最小化应用已上线 drawnix.com。
2、ragbits
Ragbits 是一个专为快速开发 GenAI 应用而设计的开源框架,提供构建可靠、可扩展应用的模块化工具。其核心功能包括灵活切换100+ LLM、类型安全的 LLM 调用、支持多种向量存储(如 Qdrant、PgVector),以及内置的开发者工具。Ragbits 还支持快速灵活的 RAG 处理,能摄取20多种数据格式、处理复杂数据并连接多种数据源。此外,它提供实时可观测性、内置测试和自动优化,并支持快速部署带有 UI 的聊天机器人界面。
3、agentic-doc
Agentic Document Extraction 是 LandingAI 推出的一款 Python 库,旨在高效地从视觉复杂的文档(如PDF、图片、URL)中提取结构化数据,包括表格、图片和图表,并以分层 JSON 格式返回精确的元素位置。该库支持处理超长文档(1000+页PDF)、自动重试、并发处理、速率限制管理,并提供丰富的辅助工具如边界框截图和可视化调试器。通过简单的 pip install agentic-doc 即可安装,并支持多种连接器(Google Drive, S3, Local Directory, URL),极大地简化了GenAI应用的文档处理流程。
AI News
1、Perplexity AI 推出 SEC 数据集成,赋能投资者轻松获取财务信息
Perplexity AI 近日宣布推出 SEC 文件访问功能,旨在革新投资者获取和理解复杂财务数据的方式。这项新功能允许所有用户直接在 Perplexity 平台上查询公司财务文档,并获得带有引用来源的自然语言答案,从而简化了原本需要专业知识或昂贵工具才能解读的监管报告。此外,Perplexity 还为 Enterprise Pro 用户提供了与Factset、Crunchbase等数据源的深度集成。同期推出的“实验室”功能,则能将提示转化为报告、仪表板等结构化项目,进一步提升了Perplexity在金融智能领域的潜力,尤其对寻求经济实惠且信息丰富的零售投资者而言。
2、Figma 发布新工具,提升 AI 设计到代码转换的精准度
Figma 近日推出开发者工具“开发模式模型上下文协议(MCP)服务器”,旨在提升 AI 将设计转化为代码的效率和精准度。该工具允许 AI 模型直接访问 Figma 的设计数据,例如图表数值和具体颜色,而非仅依赖视觉识别,从而减少大型语言模型的工作量,使开发者构思更准确地实现。目前该工具正面向部分用户进行 Beta 测试,未来计划推出远程服务器功能和更深层代码库集成。此举紧随 Figma Make 平台的正式上线,并预示着未来将有更多AI工具助力设计与开发融合,提升产品设计效率和质量。
3、阿里开源千问3向量模型,性能大幅提升,挑战谷歌和OpenAI
阿里巴巴于6月6日开源了全新的千问3向量模型系列Qwen3-Embedding,该模型基于千问3底座,在文本检索、聚类和分类等任务上性能提升超40%。Qwen3-Embedding在MTEB等专业榜单中超越谷歌Gemini Embedding和OpenAI text-embedding-3-large等顶尖模型,取得SOTA(State-of-the-Art)性能。该模型支持超100种语言,包括编程语言,并提供9款不同尺寸的开源版本及API服务,赋予开发者更大的灵活性和应用空间。
4、智源研究院发布“悟界”系列大模型,推动多模态智能新飞跃
在第七届“北京智源大会”上,智源研究院重磅发布了“悟界”系列大模型,标志着人工智能领域的技术飞跃。这些模型涵盖了从基础科学到复杂智能系统的广泛应用,包括原生多模态世界模型Emu3、脑科学多模态通用基础模型见微Brainμ、跨本体具身大小脑协作框架RoboOS2.0与具身大脑RoboBrain2.0,以及全原子微观生命模型OpenComplex2。此举旨在推动人工智能在医疗、教育、环境监测等多个重要领域的应用落地,为人类社会进步贡献力量。
5、字节跳动发布SeedEdit 3.0,图像编辑细节保持能力显著提升
字节跳动Seed团队于6月6日正式发布了图像编辑模型SeedEdit 3.0,该模型基于文生图模型Seedream3.0,通过引入多样化数据融合和特定奖励模型,显著提升了图像主体保持、背景细节处理和指令遵循能力。SeedEdit 3.0支持4K分辨率图像处理,在人像编辑、背景更改、光线转换等复杂场景中表现卓越,能实现高保真和精细化编辑,甚至能精确处理阴影等细节。该模型已在即梦网页端开启灰度测试,并将上线豆包App,极大地提升了图像编辑的可用率和效率。
6、OpenAudio 开源轻量级 TTS 模型 S1-Mini,打造超自然多语言 AI 语音
OpenAudio(Fish Audio)宣布开源其全新文本转语音(TTS)模型S1-Mini。作为S1模型的轻量化版本,S1-Mini仅0.5B参数,大幅降低计算需求,同时在超过200万小时音频数据训练下,支持14种语言及50多种情感语调,生成接近真人的自然语音。其开源发布至Hugging Face,为开发者免费提供非商业使用,极大地降低了高品质语音合成的门槛。S1-Mini在第三方基准测试中表现出色,展现出挑战行业巨头的潜力,未来有望在教育、娱乐等领域广泛应用。
7、ElevenLabs 发布 Eleven v3 Alpha 版,AI 语音实现“演技”突破
ElevenLabs 于2025年6月5日发布了其最新文本转语音模型 Eleven v3 Alpha 版,被誉为“地表最强”TTS模型。该模型通过引入 [laughs]、[whispers] 等音频标签,实现对语音情感、语速的精准控制,甚至能添加音效,使生成的语音不仅自然流畅,还能模拟真实对话中的语气变化和非语言表达,达到“演技合成”的效果。Eleven v3 支持70多种语言,并具备更强的文本理解和对话模拟能力,有望在内容创作、影视配音、虚拟助手等领域带来革新。
8、谷歌更新 Gemini 2.5 Pro,AI 性能显著提升
谷歌于6月6日发布了更新版 Gemini 2.5 Pro (06-05版本),显著提升了其AI性能。新版本在LMArena和WebDevArena等基准测试中Elo评分分别提升24分和35分,WebDevArena得分达到1443分,位居业界前列。谷歌还优化了模型的风格和结构,以提升创造性和回答清晰度,并放宽了Pro版用户的请求限制。此次更新展现了谷歌在AI领域的持续创新,预示着该版本正式上线后可能推出更具吸引力的定价策略。


本文作者:junglehxj
本文链接:
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!